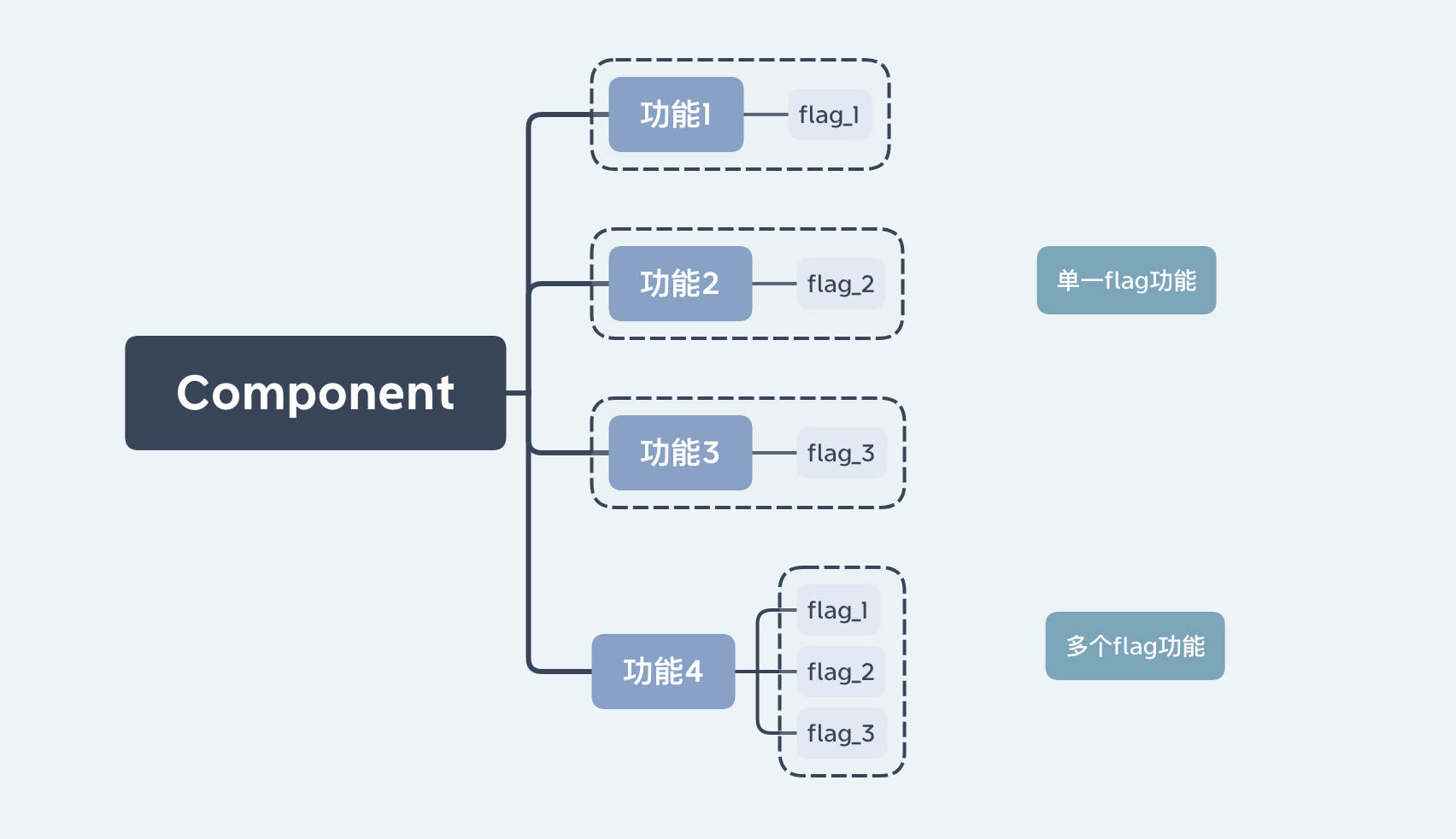
对于任何一端的应用生产中的灰度机制都异常重要,可以大幅提高应用生产业务中的可用性和可控性,对于复杂度较高的业务意义更加重大。 根据文章标题应该很多前端同学心里已经开始在构想各路骚操作的实现方式,先不着急,这篇文章的重点会介绍实现方式。 可以带着下面的问题逐个分析: 相对于 AbTest 是不是重复了?或者两者的差异是什么? 为什么会有这样的需求?前端灰度能够真正解决业务上的哪些问题? 实际的灰度需求应该是怎样的? 一、 AbTest 是个啥?如何区分和灰度的功能? 首先 AbTest 也是某种程度上的功能灰度,但是和灰度发布有着本质上的区别是两种产品类型,有的同学觉得有 AbTest 就够了,这里稍微说一下两者在前端功能上的区别,根据以往对 AbTest 在前端页面功能使用的理解,我认为主要作用是根据一定数量的样本流量(通常是有状态),通过一系列功能标签控制在前端视觉上呈现 “千人千面” 的页面功能差异,不仅可以在不同的流量终端呈现不同的功能差异,更重要的是支持这一特性后可以在产品功能上评估某一功能是否能给整体产品带来正向价值。 其中有一个很重要的环节 AbTest 通常会在前端代码中留下 hard code , 例如在一个支持点赞的 A/B 功能上可能会有如下的代码: ... 通过不同标签或者标签组合来确定某一业务功能,如下图:
这是一个很常见的 A/B 需求,当实验结束后 PM 或者数据分析师发现有 点赞 功能的转化率明显高,便会要求全量上线该功能,此时代码中的 flag 判断逻辑显示非常冗余,会在下一个发版或者实验周期进行移除相关hard code 。当然真正 A/B 实验中的 hard code 会比这个复杂很多,了解了 A/B Test 再来看灰度。
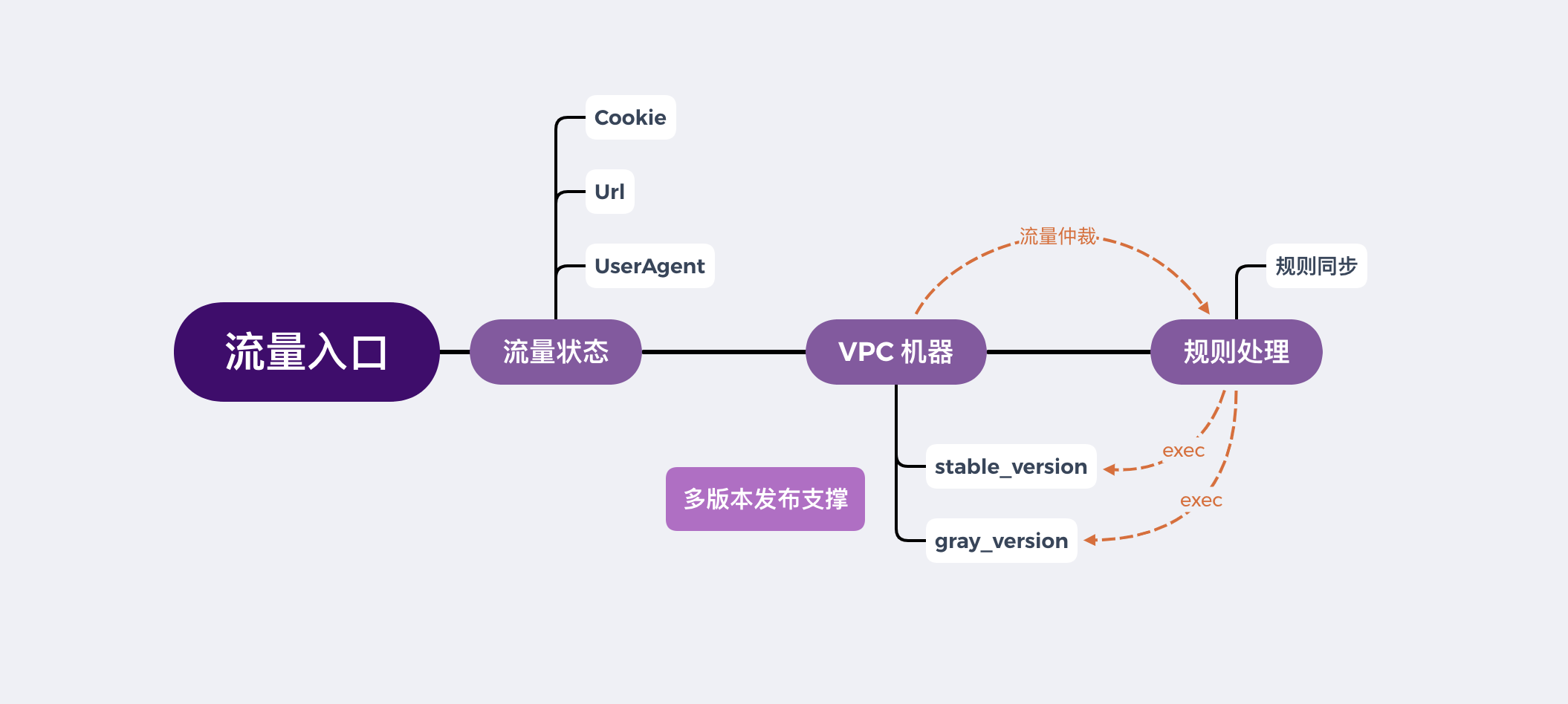
基于目前公司整体的开发部署流程,这是一张整体的灰度功能流程图,通过整体功能的了解,可以更好的区分 AbTest ,对于某些模块下面文章会深入说明。 流量入口状态通常可以有三种形势, (1)、 userAgent (2)、请求url 带指定参数 (3)、请求 cookie 中状态,结合虚机上多版本的发布支撑,通过流量的规则仲裁服务返回执行的资源版本。 和灰度本质上的一个最大的区别是代码中不存在 hard code 当前端流量进入的时候可以根据流量的某些状态来控制前端代码的版本,前提是在生产服务发布上需要支持多个版本的发布,可同时存在多个前端可用版本,根据流量规则服务控制流量所进入的版本,对于这两者的区别相信应该足够明显了。 二、为什么会有这样的需求?能够解决业务的哪些问题? 这个问题非常重要,任何一项技术的改进如果没有业务的应用场景,解决不了业务的实际痛点,这样的技术改进毫无意义,能够赋能业务才是技术的核心根基(因为这不是一个KPI项目)。
【发现问题】 回顾一下目前前端项目的发布流程,通过流程中可以发现一些问题,从测试环境到预生产环境最后到生产环境,每个环境都有专属的定位和意义,同时在不同的环境中会有不同的域名映射对应前端项目,但是通常情况除生产环境以外的环境不提供外网访问权限,这对于前端项目而言就会存在一个问题,在某些场景下需要依赖第三方服务,同时存在域名白名单机制,例如呼起第三方支付等SDK; 在这种场景下如果没有做特殊处理,只能选择在"夜深人静"的时候发布生产,然后在生产上进行某些功能验证,当然也有一种方式是绑定另外一组机器发布同一个版本的代码解析一个新的域名(域名配置调用白名单),在这新的域名上进行验证,没问题后再发布到生产用户域名上。在这个场景下其实已经能够发现一些问题了,生产上某些功能无法测试覆盖,或者说测试覆盖的成本相对较高需要新的机器和域名等资源。
上面的案例可以是一个刚需,再深入业务了解会发现一些其他问题,在生产应用的发布记录上可以看到大部分关键应用上线时间是在夜间或者说流量低峰时段,这样的操作肯定没问题降低生产风险,通过低峰流量时间段发布控制生产风险,一旦有没覆盖到测试的bug或者生产故障在流量低峰时段回滚也可以大幅降低生产风险,但是一些设备兼容性的案例就可能因为生产流量终端差异较大覆盖不到位的情况。 【分析需求】 第一个场景中出现的问题虽然已存在解决方案,但是总觉得不是特别友好,或者不是特别经济,夜间发布是降低了生产风险,对于夜间发布生产出现的问题只能等待回滚或者重新发布,无法灵活控制用户流量。基于这些问题,提出了对于前端发布生产需要能够灵活控制用户流量,能够指定部分流量进入特定新功能版本的灰度需求,同时需要降低灰度的成本,在现有模式的基础上,使用一种改动最小的方案实现灰度。 现有的前端项目部署方式
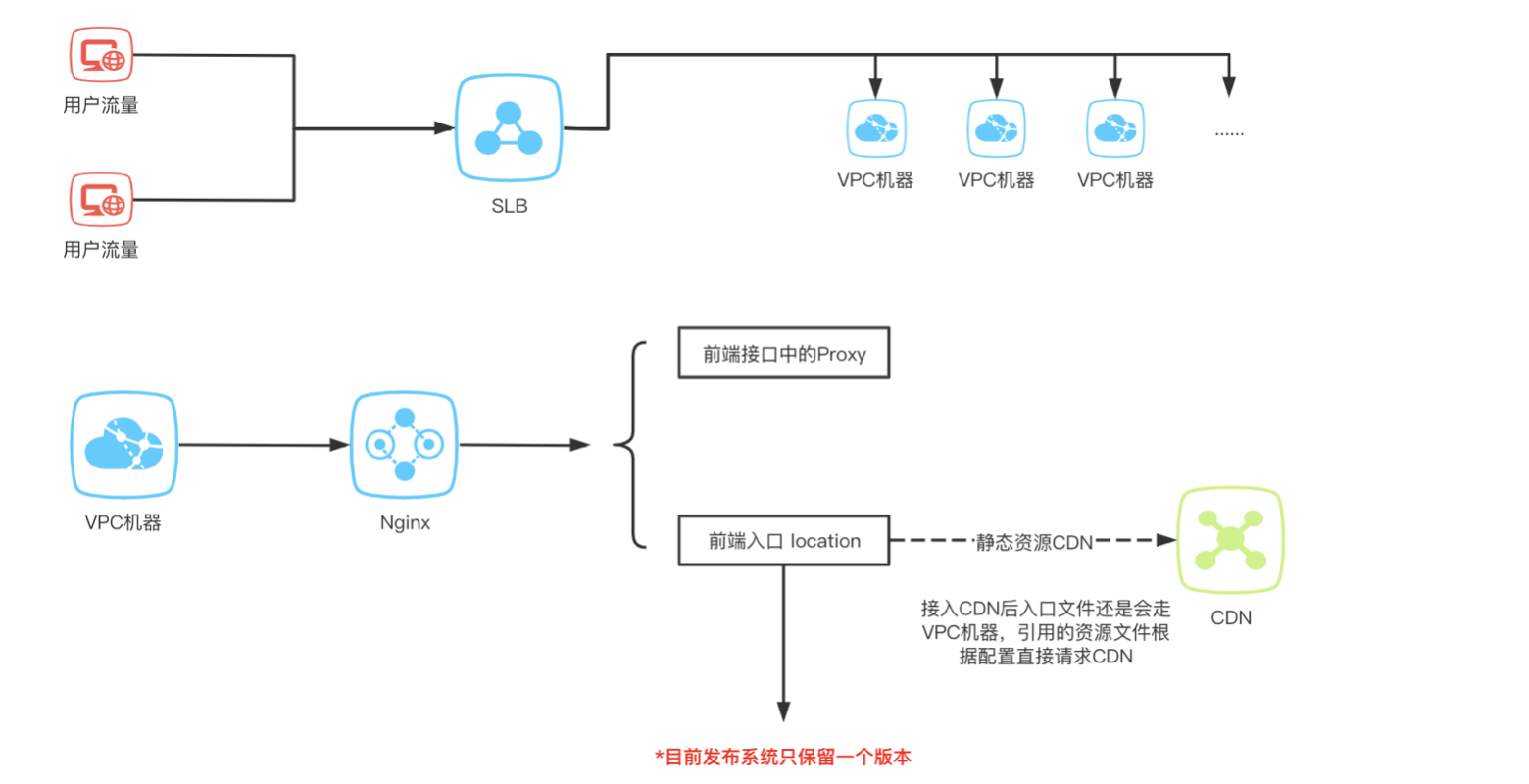
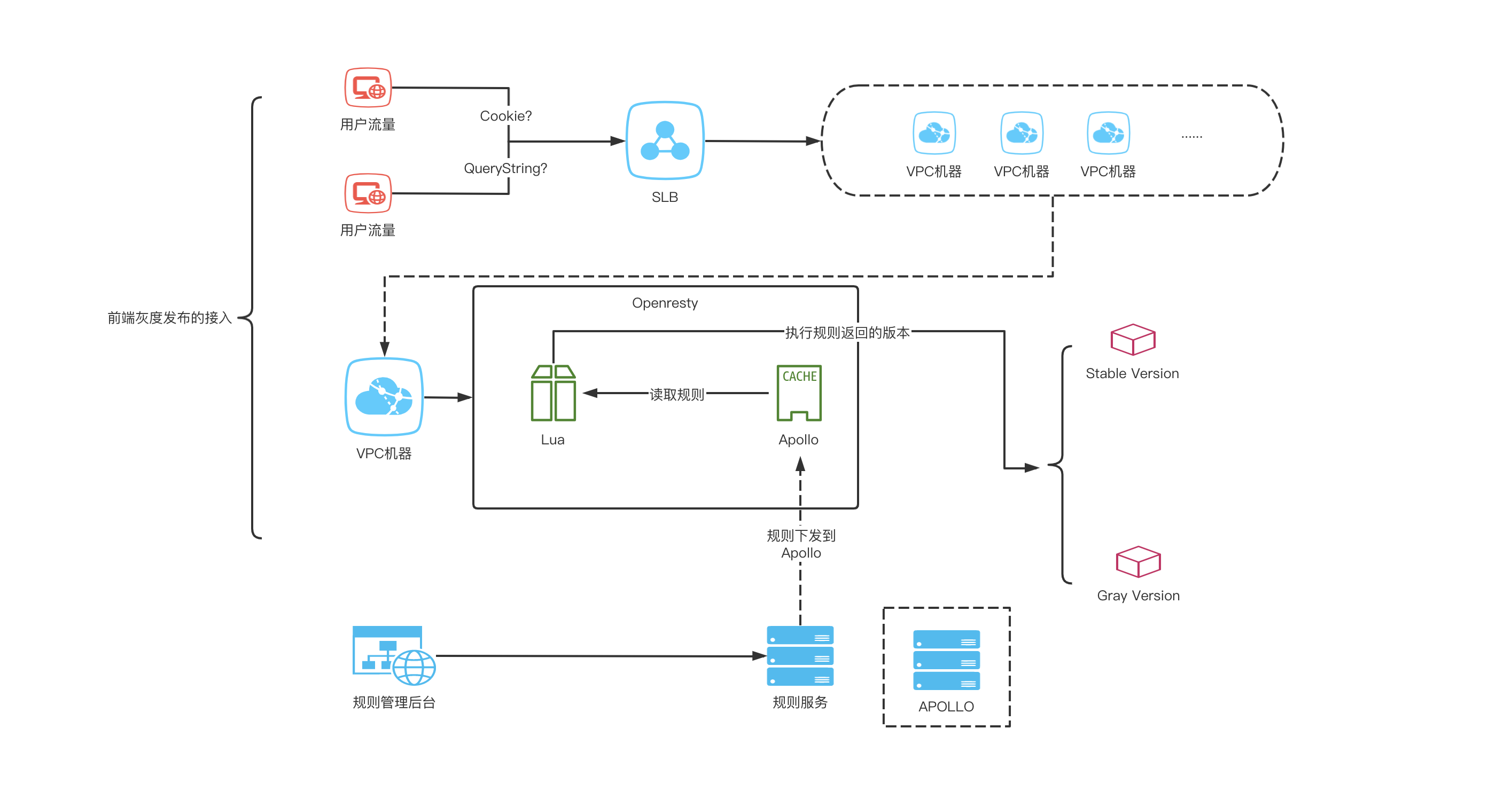
分析完需求之后,先需要深入了解当前的前端项目是如何玩转的,上面的图是目前大部分采用虚机部署前端项目生产上的运转流程。 用户流量通过 SLB 分流到不同的虚机上,前端项目部署在不同的虚机中,每台虚机都会部署 nginx ,通过 nginx 负载资源流量以及项目后端接口的网关层反向代理(主要处理前端跨域问题),同时前端资源除了静态 html 入口以外其他所有资源都会进入 CDN ,因此对于实际到达机器的流量通常情况下只有 html 当然也会因为项目的特殊性存在其他情况。 对于如何实现流量灰度其实已经有一定的思路,接着找到业务方了解他们实际业务中对于灰度的理解和实际诉求,这个过程中是需要反复沟通的,并且在不同的 BU 之间进行,需要整理出在业务上足够通用的需求,最终梳理出了一个适用目前公司大部分 C 端业务的需求。 三、实际的灰度需求应该是怎样的? 了解了前端项目部署的实际流量情况以后,再来设想一下实际灰度应该是怎样的? 域名 url 不可变,无论进入哪个版本,对于前端流量访问端,一定不能变更地址,不能因为进入灰度变更地址,这个是前提,也很好理解。 流量的状态标记,对于用户第一次访问和第n次访问在规则不变和相对环境不变的情况下是不是应该保持一致。否则对于用户而言就变成一个不确定的页面,每一次刷新看到的东西都有可能不一样,看运气,这肯定不是灰度过程希望出现的,因此对于前端的灰度而言流量的状态非常重要,那回过头看前面和业务端沟通的一个很重要的结果,就是用户流量状态标记,确定了业务场景中需要支持某一堂课 lessonId 或者某一个角色 roleId 某个设备 deviceId 等这样的自定义状态进行灰度同时需要支持 url 和 cookie 两种方式标记,另外对于没有状态的用户需要可以通过 ua方式制定某些设备终端版本的方式进行灰度。 变更灰度规则的时候,是不是能够及时生效,否则有可能出现规则发生变更但是实际流量不按规则走,规则就不可控了,因此规则的实时可控性也非常重要,业务方在做规则变更以后需要看到生产上直观的观察到当前流量状态的实时数据,让业务方心中有数,用的放心。 基于以上两种结合业务需求的设想,开始寻找一种支持如上需求的技术方案,对于生产流量需要实时可控并且规则可变更,基于目前的部署方案,在生产 nginx 新增了模块引入支持 lua 脚本运行,为了运维的稳定性将 nginx 替换为 openresty 使用上和 nginx 没有任何差异, openresty 和 lua 的结合相当顺滑,在 lua 规则脚本中处理流量的仲裁逻辑,通过使用 apollo 配置中心长轮询机制,实现规则变更同步到机器文件写入内存的共享变量中,结合灰度规则根据规则流量仲裁的结果,返回前端资源的执行版本(灰度版本或者稳定版本,在发布端需要支持两个版本的发布)。
规则管理后台基于一些状态配置应用的灰度规则信息通过 ack 后,推入 apollo 配置中心,通过 apollo 长轮询机制读取灰度规则缓存到机器(避免规则获取异常或者频繁获取的情况)并将规则缓存在内存共享到指定全局变量: 支持多种条件的规则配置,对于灰度过程中出现的异常状况,支持 一键中止 ,或者 全量灰度 秒级生效。
nginx.conf lua_shared_dict apollo_config 5m; ... listen 80;
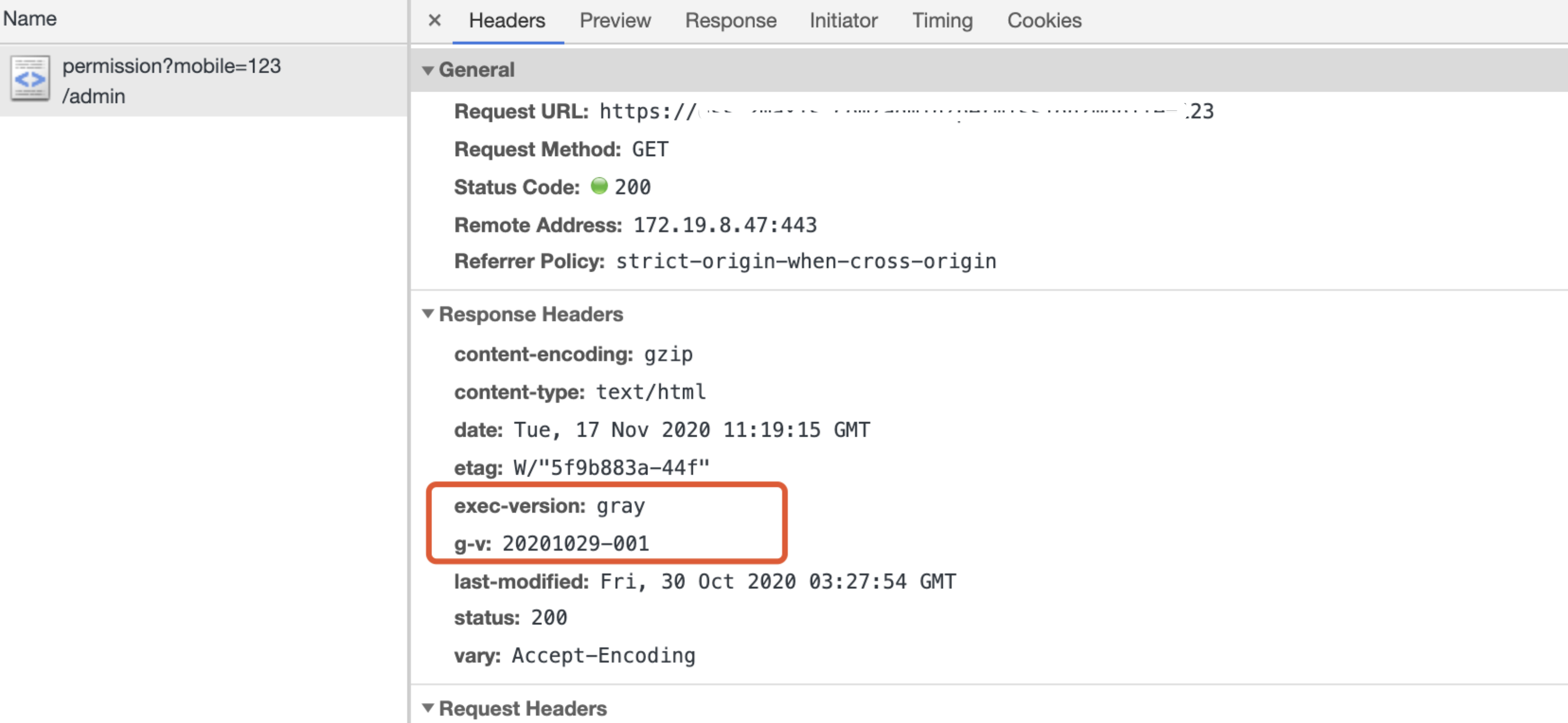
... 为了更好的在用户端发现代码执行对应的版本和发布版本等相关的数据,在响应头中添加了
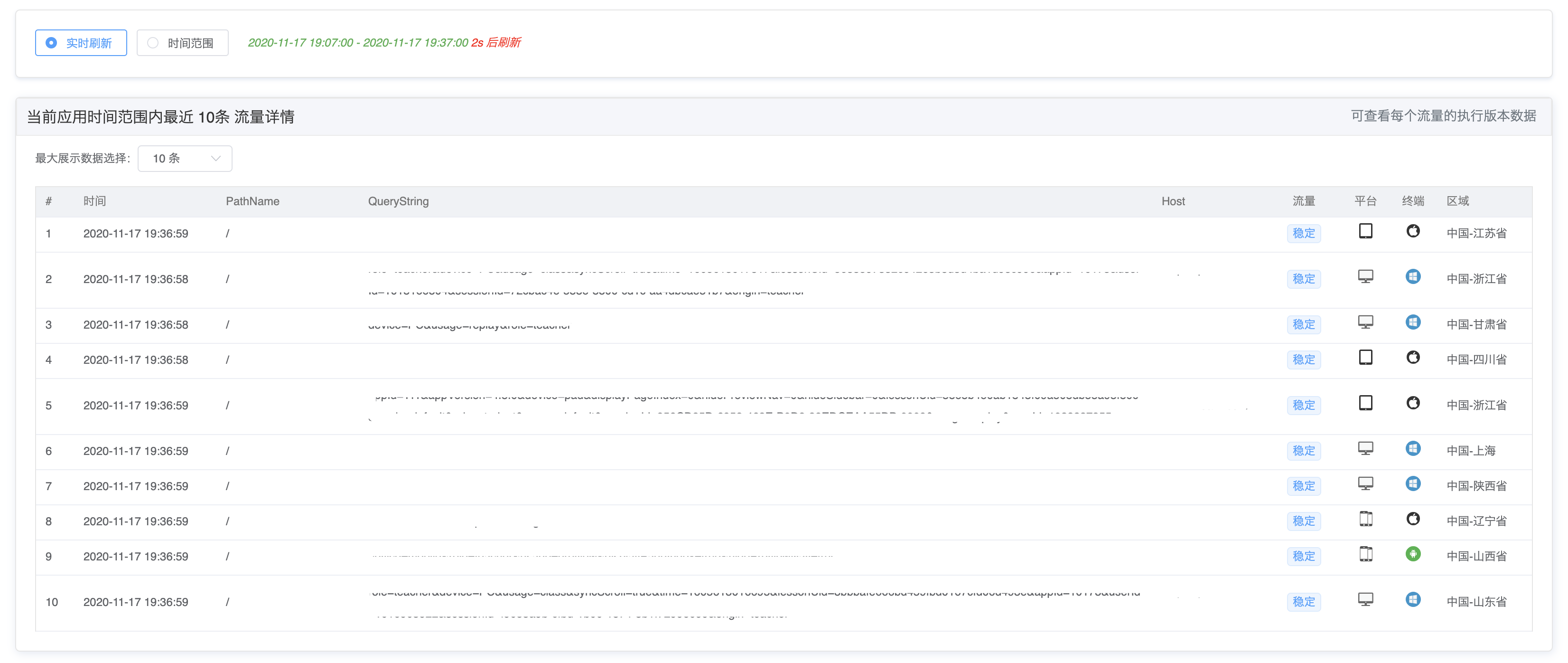
上面还有提到很关键的一个地方,灰度过程业务方非常关注过程中灰度流量的命中数据,因此在上面的代码中可以看到很多日志相关的数据,这些数据就是用来提取分析流量数据的,打入日志的数据滚动到文件,通过 filebeat 采集到 kafka 消费到 ES 兜底日志数据,同时通过 Node 进行消费清洗落库,提供前端可以查询的数据: 整体的支撑情况如下:
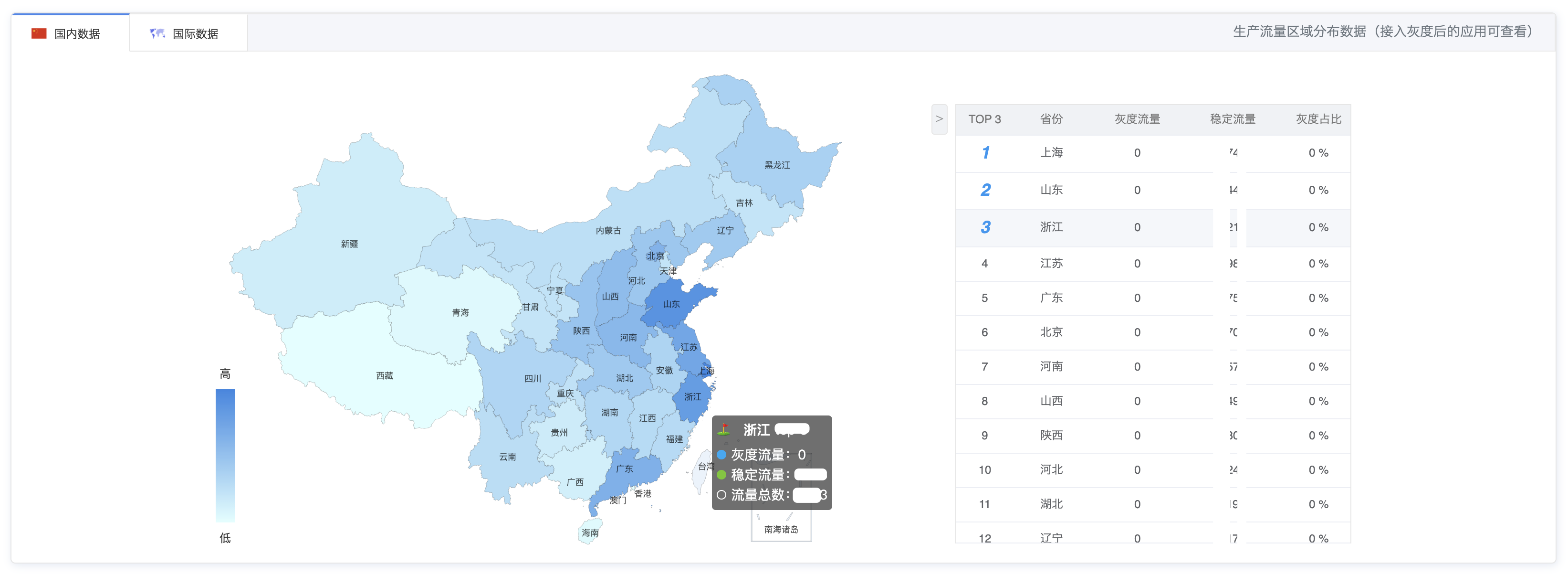
流量地区分布:
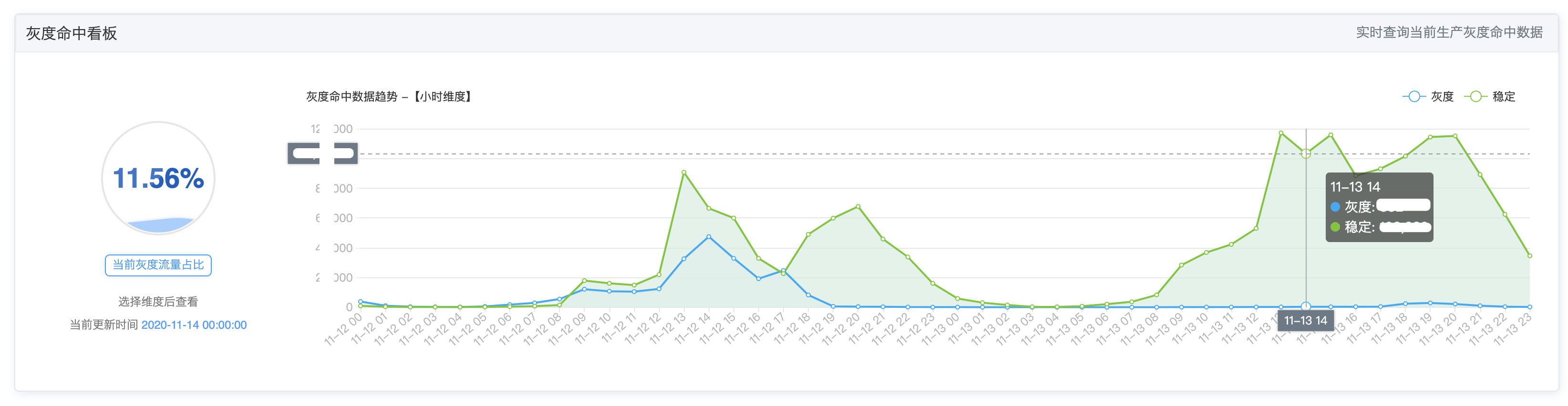
实时生产灰度百分比数据:
前端灰度在实践落地过程中遇到非常多的细节问题和复杂场景,好在成功扛过了公司几个高流量核心前端项目的接入落地,未来还有更多横向可扩展的需求,例如基于地域的灰度,完全无状态的百分比灰度等甚至可扩展到后端服务网关级别的灰度,或许也会在适当的时机根据公司业务需求程度择机迭代。 另外对于改造成当前灰度模式的性能上是否有影响的疑问,都有做过压测,并有实际的压测报告,结果几乎没有影响。 |
Archiver|茂业软件开发工作室 ( 蜀ICP备2020032308号-2 )
GMT+8, 2026-7-27 05:48 , Processed in 0.012311 second(s), 13 queries .

微信二维码
扫码添加微信好友